※コードの説明はすこしづつ追加しています。('24/9月)
しょくぶつ(^ ^)です。
だいぶ準備に苦労しましたね。
ようやく!!
「予測モデルを作成」ですよ!!
CNN(畳み込みニューラルネットワーク)を使って学習し、予測モデルを作成します。
Pythonでコードを作成するのはちょっと大変なのですが、頑張りましょう。
(1) 学習データを1つのファイルにまとめます。
まず、前回で水増しした、フォルダに分類された画像データ一式を1つのファイルにまとめてみましょう。
フォルダ” img_folder'”を作成して、画像データ一式を入れてください。
そしてコードを実行してください。
すると、” dataset.npz”というファイルにまとめます。
ここでさらりと画像データを
img3 = np.array(img2) #画像をArray of unit8に変換
img4 = img3[:,:,[2,1,0]] # RGBからBGRに変換(予測時はcv2読込みのBRGという2行で整形しているのですが、実は鬼門です。
独自画像データを使って、モデルを作って、ぜんぜん精度が出ない、というときは、ここでつまづいている恐れ大です。
ここで予測時に取り込む画像データときちんとデータ型(Array of unit8やらfloat32やら)やRGB順番(RGBかBGRか)を合わせる、もしくは、取り込みデータ側の方をここで指定した型式に合わせてください。
本コードではOpenCVで取り込む画像データの方に合わせるため、上記の2行のように整形しました。
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 16 17:03:04 2023
@author: Plant-smile
"""
# プライベートファイル"CNN-datasaveV2p1.py"を公開用に修正
import numpy as np
import glob
from PIL import Image
from sklearn.model_selection import train_test_split
#親フォルダを指定
base_folder='img_folder'
#親フォルダ内の子フォルダのパスを取得
dirs=sorted(glob.glob(base_folder+'/*'))
#入出力データを入れる箱を準備
Xdata=[]
Ydata=[]
num_buki = len(dirs) # ブキの数。ちなみに'24/6現在で143種+NG画像3種=146
#子フォルダごとに処理を行う
for i in range(num_buki):
#子フォルダ内の全画像のパスを取得する
pics=sorted(glob.glob(dirs[i]+'/*.png'))
#子フォルダ内の全画像に対して処理を開始する
for j in range(len(pics)):
img=Image.open(pics[j])
img2 = img.resize((64,64)) #64x64にリサイズ
img3 = np.array(img2) #画像をArray of unit8に変換
img4 = img3[:,:,[2,1,0]] # RGBからBGRに変換(予測時はcv2読込みのBRG画像を使うので)
Xdata.append(img4)
Y=np.zeros(num_buki,np.uint8) #ゼロで初期化した配列を用意
Y[i]=1
Ydata.append(Y)
#作成したデータをnumpy配列に変換する
# 既にnumpy配列になっているから不要では?
# 必要! そうしないと、Xdata, Ydataはともに[Numpy, Numpy, Numpy, numpy...]というリストなので、
# これを(5160, 64, 64, 3)のArray of float64, (5160, 146)のArray of unit8 にできないから。
# Xdataは輝度を正規化するため255で割っている。
Xdata=np.array(Xdata)/255
Ydata=np.array(Ydata)
print(Xdata.shape)
print(Ydata.shape)
# データの分割(教師データやテストデータを作る)
print("# データの分割(教師データやテストデータを作る)")
train_images, test_images, train_labels, test_labels \
= train_test_split(Xdata, Ydata, test_size=0.2)
np.savez("dataset.npz",train_images, test_images, train_labels, test_labels)
# 保存したnumpyデータ読み込み
#npz = np.load("dataset.npz")
#train_images_2=npz['arr_0']
#test_images_2=npz['arr_1']
#train_labels_2=npz['arr_2']
#test_labels_2=npz['arr_3']
(2)予測モデル作成
※コードの説明はすこしづつ作成中です。すこし時間をください。
次のコードを実行して、予測モデルを作成します。
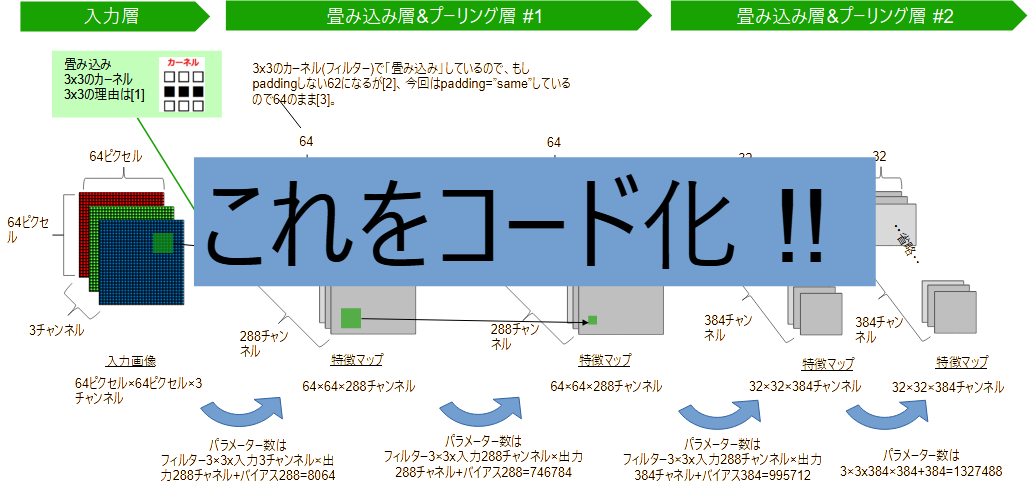
下の図のようなモデルをコード化したものです。

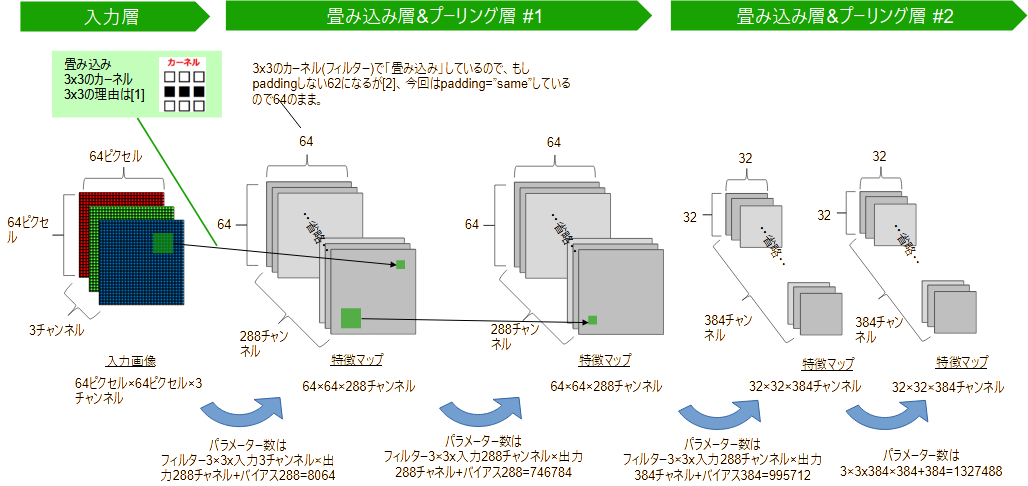
ここまで、自分用の学習モデルを作りたいということで読み進めてきた方も多いと思います。
しかしここで謎の数字が多数表れて、困惑されたのではないでしょうか。
そんな場合は、まずは、次の数値を自分用に修正すればOKです。
-
入力画像サイズ たとえば画像が128x128にしたい場合は
model.add(layers.Conv2D(288,(3,3),activation="relu", padding='same', input_shape=(64,64,3)))のinput_shapeを
(128,128,3)にします。 -
出力サイズ たとえば分類したいのが10種類だけとしたいとき。
このコードだと、model.add(layers.Dense(num_buki, activation="softmax"))・・・の
num_bukiで出力サイズを設定しているので、これを10に変更します。
逆に、謎の数字をどうやって決めたらよいか分らずネットをさまよいまくって、イライラしている方も多いでしょう。
私もそうでした (-_-) 。
決め方はなるべく早くアップしますが、お急ぎの方はコードだけですがご覧ください。
『なぜこんな形のモデルなのか?』
モデルの形(アーキテクチャ)ですが、これは、CNNの代表的なもののうち「VGGNet (2014)」というものを参考にしています。
ご参考: たとえば畳み込みニューラルネットワークの代表的なモデル - KIKAGAKU
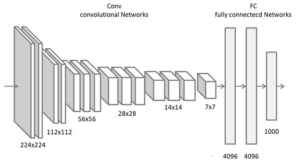
他にもアーキテクチャはあるのですが、しょくぶつ(^ ^; 、この分野は初心者です。
一番マネしやすかったものを採用したのは言うまでもありません。
さて、コードを実行してください。
予測モデルは
buki-classification-mod.keras
という名前で保存されます。
なお、コードを実行して学習させるのはかなり時間がかかります。
ハイパーパラメーターの値を大きくすると1日かかってしまいますが、古いノートPCでもなんとかなります。
が !
GPUがあるPCだと「GPUコンピューティング」で数十倍速く学習できます。
その方法は、既に下記URLに記載しました。
逆な言い方をすると、この方法を使わないとGPUは使われません。
ちょっと難しいですが、噛みつき甲斐がありますよ。
Tensorflow「2.16」: WSL2環境下でGPUを使う方法(その1) - しょくぶつ(^ ^)のブログ (plant-smile.work)
Tensorflow「2.16」: WSL2環境下でGPUを使う方法(その2) - しょくぶつ(^ ^)のブログ (plant-smile.work)
Tensorflow「2.16」: WSL2環境下でGPUを使う方法(その3) - しょくぶつ(^ ^)のブログ (plant-smile.work)
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 16 17:03:04 2023
@author: plant-smile
"""
# プライベートファイル"CNN-clas_orgV2.py"を公開用に修正
# Tensorflow 2.16で動作確認済み
import numpy as np
import tensorflow as tf
from keras import models
from keras import layers
from tensorflow.keras import optimizers
from keras.callbacks import EarlyStopping
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
# # # メイン # # #
# 保存したnumpyデータ読み込み
npz = np.load("dataset.npz")
train_images = npz['arr_0']
test_images = npz['arr_1']
train_labels = npz['arr_2']
test_labels = npz['arr_3']
num_buki = test_labels.shape[1]
print("num_buki=",num_buki)
print("データを読み込みました。")
print(train_images.shape, test_images.shape, train_labels.shape,
test_labels.shape)
input("CNNの訓練を実施(Enter)")
# 【Scikit-learn】Olivetti facesデータセットで畳み込みニューラルネットワーク(CNN)して
# みる
# https://banga-heavy.com/%E3%80%90scikit-learn%E3%80%91olivetti-faces%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88%E3%81%A7%E7%95%B3%E3%81%BF%E8%BE%BC%E3%81%BF%E3%83%8B%E3%83%A5%E3%83%BC%E3%83%A9%E3%83%AB%E3%83%8D/
# 【AI】サンプル画像の自作から画像分類CNNモデル構築までを実演!
# まるさんかくしかく の画像を読み込んで分類
# https://www.higashisalary.com/entry/ai-cnn-sample#google_vignette
# やたらと広告が出る・・・
# https://www.sejuku.net/blog/64372
DEVICE = '/GPU:0'
with tf.device(DEVICE):
# CNNモデルの構築
print("CNNモデルの構築")
model=models.Sequential()
# 畳み込み処理1回目(Conv→Conv→Pool→Dropout)
model.add(layers.Conv2D(288,(3,3),activation="relu", padding='same',
input_shape=(64,64,3)))
model.add(layers.Conv2D(288,(3,3),activation="relu", padding='same'))
model.add(layers.MaxPooling2D(2,2))
model.add(layers.Dropout(0.3))
# 畳み込み処理2回目(Conv→Conv→Pool→Dropout)
model.add(layers.Conv2D(384,(3,3),activation="relu", padding='same'))
model.add(layers.Conv2D(384,(3,3),activation="relu", padding='same'))
model.add(layers.MaxPooling2D(2,2))
model.add(layers.Dropout(0.3))
# 畳み込み処理3回目(Conv→Conv→Pool→Dropout)
model.add(layers.Conv2D(96,(3,3),activation="relu", padding='same'))
model.add(layers.Conv2D(96,(3,3),activation="relu", padding='same'))
model.add(layers.MaxPooling2D(2,2))
model.add(layers.Dropout(0.3))
# 畳み込み処理4回目(Conv→Conv→Pool→Dropout)
model.add(layers.Conv2D(128,(3,3),activation="relu", padding='same'))
model.add(layers.Conv2D(128,(3,3),activation="relu", padding='same'))
model.add(layers.MaxPooling2D(2,2))
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(500, activation="relu"))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(num_buki, activation="softmax"))
# CNNモデルの訓練
#訓練時にメモリオーバーした際は、
#(1) batch_sizeを小さくする。 (2) その分、optimizerのlearning_rateも小さくする
print("CNNモデルの学習")
input("Enterでスタート")
# 最適化 - Keras Documentation https://keras.io/ja/optimizers/
# 下記はTF2.3未満。 TF2.16では使えない。
# lr :learng_rate defaultは0.01。メモリオーバーしたので、batch_sizeとともに
# 半分にした。
#sgd = optimizers.SGD(lr=0.005, decay=1e-6, momentum=0.9, nesterov=True)
#もしTF2.3以下で使える学習モデルを作るならば下記。
#sgd = optimizers.legacy.SGD(lr=0.005, decay=1e-6, momentum=0.9,
# nesterov=True)
# for TF >=2.3
# https://stackoverflow.com/questions/74734685/how-to-fix-this-value-error-valueerror-decay-is-deprecated-in-the-new-keras-o
lr_schedule = optimizers.schedules.ExponentialDecay(
initial_learning_rate=1e-2,
decay_steps=10000,
decay_rate=0.9)
sgd = optimizers.SGD(learning_rate=lr_schedule)
model.compile(optimizer=sgd,
loss="categorical_crossentropy",
metrics=["accuracy"])
callbacks=[EarlyStopping(monitor="val_accuracy",patience=5)]
results=model.fit(train_images, train_labels,
epochs=100,
batch_size=10,
verbose=1,
callbacks=callbacks,
validation_data=(test_images,test_labels))
model.summary()
# グリッドサーチで最適化したモデルを保存するには?
#https://teratail.com/questions/219515
model.save('buki-classification-mod.keras')
