“AndroidスマホのTermux上でPythonを動かして、Tensorflow liteのコードを実行するまで”
( はてなブログから引っ越し '24/8/16 )
しょくぶつ(^^)です。
では、こんな感じでコードを動かしていきます。
しかし、前回から中断したことがほとんどでしょう。
再開方法を示します。
途中でやめて再開するときは~Python仮想環境まで
スマホとパソコンとの接続は、パソコンをスリープさせたりすると接続が切れてしまいます。
そんなときは、次のコマンドを実行してください。
(1)スマホ側のTermuxを閉じているときは下記を実行。
- Termuxを開く
- Termux上で次のコマンドを打ってsshを起動。なお、"↑"を押すと1回前に実行したコマンドが表示されます。もう何回か"↑"を押すと、下記のコマンドが出てくるはずです。
※ sshではなく sshd であることに注意。
※実行しても特にメッセージは出ません
~$ sshd- Termux上で次のコマンドでipアドレスを確認。
ただし、前回と変わっていないことがほとんどです。
~$ ip -4 a
・・・
inet (スマホのipアドレス)/24
・・・(2) Powershell上からsshでTermuxと接続。
例: PS C:\Users\(ご自身の環境に依存)> ssh u0_a435@192.168.11.20 -p 8022
(3) ubuntu環境に入り、更にpython仮想環境に入る。
~$ proot-distro login ubuntu root@localhost:~# py3102
無事に下記のように再開できたでしょうか?
(py3102) root@localhost:~#
1. 必要な機器
必要な機材は次の通りです。
そのほか、windows PC と SDカード は使うと便利。
-
android スマホ ※ネットワークは必要ありません
-
HDMIキャプチャー機器
動作確認済み エレコムのAD-HDMICAPBK -
HDMIケーブル, 3本
-
Nintendo Switch本体
-
ドック
-
★HDMI分配器(HDMIスプリッターとも言います。)
注意! 「HDMI切替機」ではありません。
私はグリーンハウスのGH-HSPA2-BKを使っています。
(現在はGH-HSPG2-BKという後継品あり。'24/9月現在だとヨドバシで1,900円くらい。)
図にするとこんな感じです。
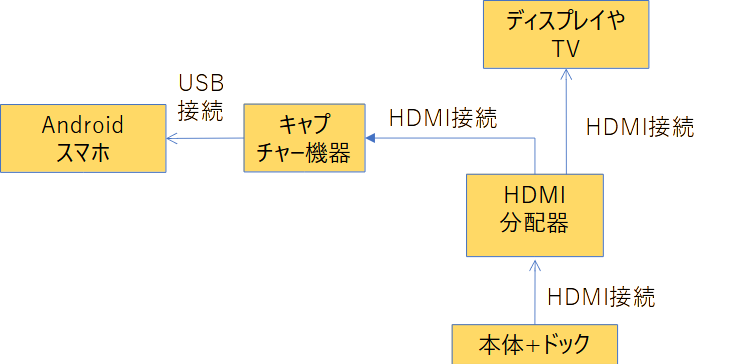
必要な機器、その接続
コードをスマホにコピーする方法
コードをスマホにコピーする方法はいろいろあるのですが、次の「スマホをストレージとしてwindowsと接続」する方法が一番お手軽です。
(1)あらかじめwindowsにコードをダウンロード
(2)スマホをストレージとして接続
(3)Windows PCから、スマホのSDカード側の、たとえば次の場所へ、コードなどを移動。
SDカード > Pictures > Screenshots
(4) Termux上で作業ディレクトリを作成 ※ 初回だけ
(py3102) root@localhost:~# cd ~ (py3102) root@localhost:~# mkdir workspace
(5)Termux上で、cpコマンドを使って作業ディレクトリにコードをコピー
例: "testcode.py"というファイルの場合
(py3102) root@localhost:~# cp
/sdcard/Pictures/Screenshots/testcode.py ~/workspaceコード内の画像取り込みパラメーター修正
画像取り込みはpython側では実現できなかったので「USBカメラ」アプリで行います。(インフィニテグラ(株)という信頼できるカメラ技術の会社の無料アプリです。)
「USBカメラ」のPlayストア紹介画面
このとき、スマホとキャプチャー機器の組み合わせによって画像サイズが変わってしまいます。
そこで画像取り込みパラメーターを手動で修正します。
本コードには ダイアログボックスに入力 とか、 自動 とか、 おしゃれな 機能はありません。
コード内の数値を書き換えていきます。
まず、キャプチャー機器をUSB端子に接続し、次に「USBカメラ」を起動しましょう。
キャプチャー画像は見られるでしょうか?
なんか、スマホにSwitchの画面が映って、おお~って感じですよね。
スマホにSwitchの画面が映りました!!
次はお好み次第ですが、私は 全画面表示 にしました。
そうしたら、電源ボタン + 音量ダウンボタン などでスクリーンショットを撮ってください。
スクリーンショットは /sdcard/Pictures/Screenshots/ に保存されるので、上記の「コードをスマホにコピーする方法」を参考にして、スクリーンショットをパソコン側にコピーしてください。
そして、スクリーンショット自体の画像サイズと、その画像内のキャプチャー画面のサイズを、パソコンなどで調べて下さい。
たとえば「ペイント」で開いて、左下に表示されるカーソル位置を使います。
そしてコード内の
# # # # # #cap_dev_no = 1 cap_W = 1920 # キャプチャー画像の横幅 cap_H = 1080 # キャプチャー画像の縦幅 cap_Left = 215 # キャプチャー画像の横の原点。 cap_Right = cap_Left + 1920 cap_Top = 0 #キャプチャー画像の縦の原点 cap_Bottom = 1080 # # # # #
6個の変数、cap_W, cap_H, cap_Left, cap_Right, cap_Top,cap_Bottomを修正してください。
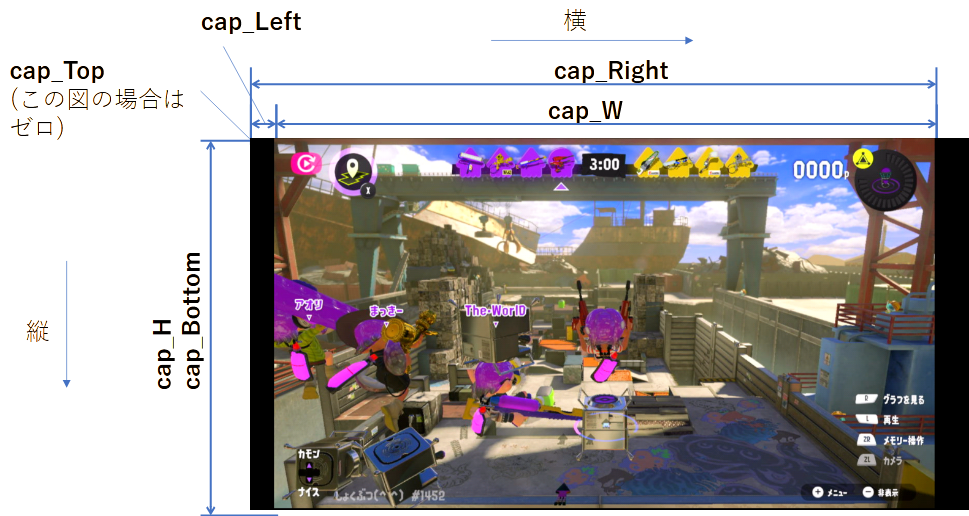
コードを動かす方法
いよいよコードを動かしていきます。
コード等のファイルをスマホ上にコピー
次のURLに私が作成したファイルをアップロードしました。
※ コードは本ブログの一番最後に記載します。
このうち、次のファイルを任意の場所 (たとえば作業ディレクトリ ~/workspace ) にコピーしてください。
buki-classification.tflite
学習データです。buki-spe-list.csvブキとスペシャルの対応表です。
TFlite-predictV0-in-phone.pyコードです。
Pythonコードの実行 方法(1)
このあと方法(2)も紹介しますが、この方法(1)が一番簡単です。
この方法(1)は、次のコマンドを実行するだけです。
(py3102) root@localhost:~# python TFlite-predictV0-in-phone.py
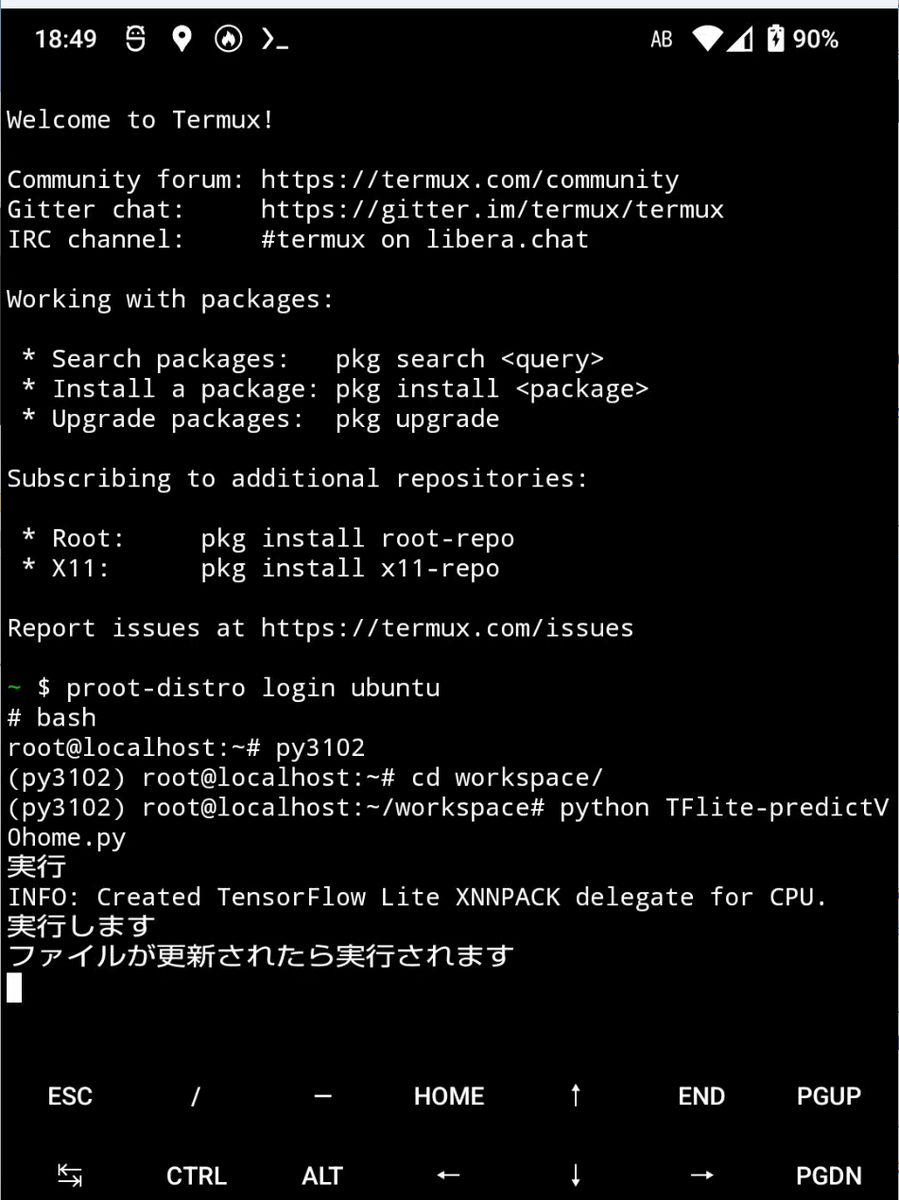
スマホ上のコード実行の様子
Pythonコードの実行 方法(2)
この方法(2)は、Jupyter labを用意して実行するものです。
※次のURLを参考にしました。
https://www.silhouette-designer.com/the-real-pocket-note-pc-cosmo-communicator-termux-jupyterlab/
i) Jupyterlab のインストール
(py3102) root@localhost:~# python -m pip install jupyterlab
ii) jupyterlabのパスワードを設定
(py3102) root@localhost:~# jupyter lab password
iii) jupyterlabを起動
(py3102) root@localhost:~# cd ~/workspace (py3102) root@localhost:~#jupyter lab --allow-root --ip=* --no-browser
iv) Androidのブラウザを起動
そして、Jupyter lab の起動画面にも表示されている
http://localhost:8888/lab
もしくは
http://127.0.0.1/lab
を入力して開きます。
するとjupyterlabの画面となります。
v) コード( TFlite-predictV0-in-phone.py ) を開きます。
具体的には、 画面左のフォルダのアイコンをクリック、次に、 ファイル名をダブルクリック です。
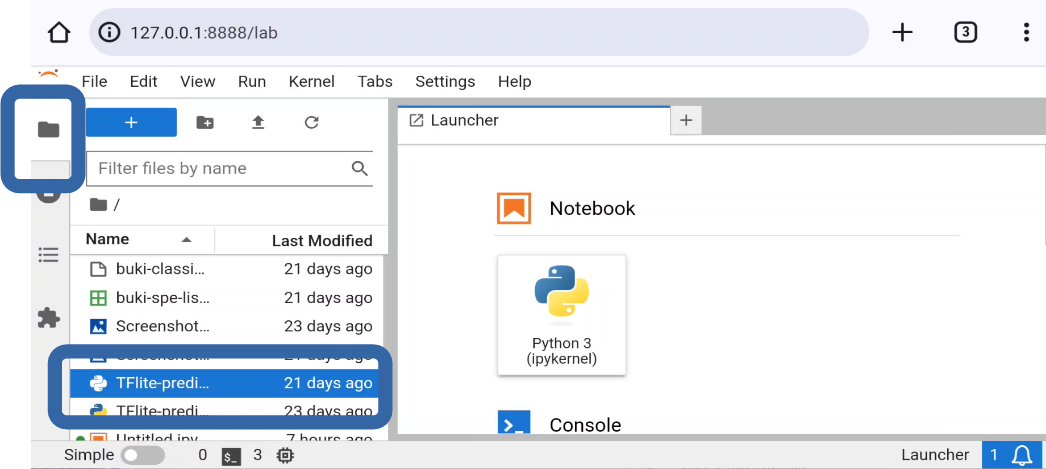
スマホ上でJupyter labが起動
vi) notebookをクリックします。

notebookをクリック
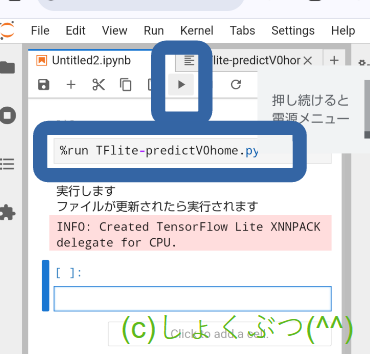
vii) %run TFlite-predictV0-in-phone.py と入力して、実行します。
なお、この画面のように縦画面で使うときは、viewのShow Left Sidebarをオフにすると開いたファイルが大きく表示にできます。
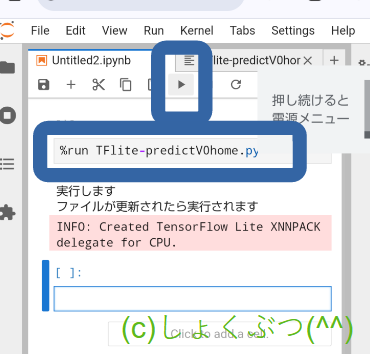
%run (コード名) と入力、そして実行!!
キャプチャー機器からの画像取り込み
Pythonコード単体ではキャプチャー機器から画像を取り込めないので、上述の「USBカメラ」アプリと連携します。
・ 「USBカメラ」起動
Termuxやブラウザは終了しないでそのままにして、「USBカメラ」を起動してください。
・ 画像取り込み
上記の「コード内の画像取り込みパラメーター修正」と同じ状態で、画像を取り込みます。(私は 全画面表示 にしました。)
画面上に敵・味方のブキ一覧が表示されたら、電源ボタン + 音量ダウンボタン などでスクリーンショットを撮ってください。
5~10秒くらいで「スプラの敵のスペシャルを声でお知らせ」
スクリーンショットを撮ると、/sdcard/Pictures/Screenshots/の中のファイルが増えます。
それをPython側が検知して、自働で機械学習モデルを使った予測(画像を見てブキを判別)が始めます。
5~10秒くらいで「スプラの敵のスペシャルを声でお知らせ」してくれるはずです !!
いかがでしょうか?
「コード内の画像取り込みパラメーター修正」とか、うっかり全画面表示を解除したり、ミスしなければ、Windows上で実行したときと同じような正確さで、お知らせしてくれたはずです。
感想
おつかれさまでした!!
初心者の方は仕組みは分からないにしても、機械学習を使った画像処理のPythonプログラムをスマホで実行できたわけです。
しかも、スマホでのLinux, その下でのubuntu, さらにその下でのPython, またまたその下でのTensorflow, OpenCVを使える環境もゲットできました !!
なお、今回までに紹介した方法ではTensorflowはlite版しか使えなかったので予測だけで、学習はできませんでした。
しかし、無料のTermux (そう、今回までは全て無料でできるんです) ではなく、2000円弱のPydroid3を使えば、スマホでもちゃんと学習も実行できます。
これもいつか紹介しますね。(リクエストがあれば優先度を上げます)
さらにいうと、Windows上で動いていたコードをスマホで動かせたのは大感激です !!
たしかに、前回のような何カ所もの修正が必要でした。
それでも、算数がわりとめんどうで私としては一番いじりたくない、画像のカットや変形のコードについて、修正がゼロだったのは大きかったです。
ほかの活用法もどんどん考えたいと思います。
今回使ったコード
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 31 13:01:48 2023
@author: plant-smile
"""
try:
# linux
import tflite_runtime.interpreter as tflite
except ImportError:
# win
from tensorflow import lite as tflite
import numpy as np
import pandas as pd
#import pyttsx3
import cv2
import matplotlib.pyplot as plt
from matplotlib.image import imread, imsave
import subprocess
import glob
import os
import time
from PIL import Image
Image.LOAD_TRUNCATED_IMAGES = True
import datetime
# # # # #
#cap_dev_no = 1
cap_W = 1920
cap_H = 1080
cap_Left = 215 # 2280*1080時左右非対称 120# 2160*1080時
cap_Right = cap_Left + 1920
cap_Top = 0
cap_Bottom = 1080
# # # # #
def original_resize(img_loc, photo_size_loc):
# 画像img_locを、縦横photo_size_locの正方形に、縮小
# Pillow(PIL)のImageモジュール, resize を使うとアスペクト比が変わってしまうので、
# アスペクト比を変えないでサイズ変更する関数を作りました。
# 予測性能がアップ? した気がします。 x: width方向, y: height方向
#
# 真っ黒な、縦横photo_size_locの正方形の画像を用意。
base_img=np.zeros((photo_size_loc,photo_size_loc,3),np.uint8)
#
img_height, img_width, img_c = img_loc.shape
x_ratio = photo_size_loc / img_width
y_ratio = photo_size_loc / img_height
if x_ratio < y_ratio: # widthの方が大きい、つまり横長の場合
resize_heght = round(img_height * x_ratio)
resize_sizes = (photo_size_loc, resize_heght)
img_loc=cv2.resize(img_loc, resize_sizes)
# 上下に空いた隙間は真っ黒ではなく、元画像の端部をコピーして埋めます。
for i in range(int(photo_size_loc/2)):
base_img[i]=img_loc[0]
for i in range(int(photo_size_loc/2),photo_size_loc):
base_img[i]=img_loc[ resize_heght - 1]
# base_img と img_loc を合成
height0 = int( ( photo_size_loc-resize_heght )/2 )
base_img[height0:resize_heght + height0,:,:]=img_loc
else: # 縦長の場合 今回は縦長にはならないはずですが、念のため。
resize_size = (round(img_width * y_ratio), photo_size_loc)
# base_img と img_loc を合成
img_loc=cv2.resize(img_loc, resize_size)
base_img[0:resize_size[1],0:resize_size[0],:]=img_loc
return(base_img)
'''
スマホ版では削除した部分(OpenCVによるカメラからの画像取り込み)
'''
def cut_img_to_XPdata(img_loc):
# 画面右上に表示される相手側のブキ画像4個(幅:高さ=80:64=5:4)を切り出してXPdataに格納
# すこし大きめに切り出している理由は、ガチマッチ進行によるブキ画像の拡大表示に対応するため。
XPdata =[]
Img_cut_org = []
Htop, Hbottom = int(16/720*cap_H), int((16+64)/720*cap_H)
Wtop = int(692/1280*cap_W)
for i in range(4):
Wbottom = Wtop + int(80/1280*cap_W)
img_cut = img_loc[Htop: Hbottom, Wtop: Wbottom]
# オリジナルのカット画像の保管(ファイル保存したいとき用)
Img_cut_org.append (img_cut)
# サイズを64x64に統一
img_cut = original_resize(img_cut, 64)
XPdata.append (img_cut)
Wtop = Wtop + int(59/1280*cap_W)
# np.arrayが必要な理由。
# 1. tensorflowで作成したモデルへの入力はnp.arrayである必要があるため。
# 2. [NParray,NParray,NParray,NParray,]というリストを
# (4, 64,64,3)のnp.array of unit8に、、さらに/255することでfloat64 に変換するため。
XPdata=np.array(XPdata)/255
return(XPdata, Img_cut_org)
def show_predict_buki(predicted_no, Img_cut_org):
print("取り込んだ画像と予測categoriesの表示")
# Pillow(PIL)を使って4個のブキ画像を並べて表示します。
plt.figure(figsize=(15,15))
for i in range(4):
plt.subplot(2,2,i+1)
plt.xticks([])
plt.yticks([])
img_cut = cv2.cvtColor(Img_cut_org[i], cv2.COLOR_BGR2RGB)
plt.imshow( img_cut )
plt.xlabel( categories[ predicted_no[i] ] )
plt.show(block=False)
def speak_buki(predicted_no):
# ブキ名を発音します。
for i in range(4):
#engine.say( name_buki[ predicted_no[i] ] )
#engine.runAndWait()
cmd = "termux-tts-speak " + str(name_buki[ predicted_no[i] ])
tmp=subprocess.getoutput(cmd)
print( name_buki[ predicted_no[i] ] )
def speak_special(predicted_no):
# スペシャル名を発音します。
#engine.say('スペシャルは')
#engine.runAndWait()
tmp=subprocess.getoutput("termux-tts-speak スペシャルは")
print('スペシャルは')
for i in range(4):
#engine.say( name_special[ predicted_no[i] ] )
#engine.runAndWait()
cmd = "termux-tts-speak " + str(name_special[ predicted_no[i] ])
tmp=subprocess.getoutput(cmd)
print( name_special[ predicted_no[i] ] )
def save_cut_img(predicted_no, Img_cut_org):
# 画像の保存
now = datetime.datetime.now()
for i in range(4):
f_name = '/sdcard/Pictures/Screenshots/cap_' \
+ categories[ predicted_no[i] ] +str(i) \
+ now.strftime('%Y%m%d_%H%M%S')
cv2.imwrite(f_name + ".png", Img_cut_org[i])
if __name__ == '__main__':
# モデル読み込み (Tensorflow使用, 畳み込みニューラルネットワーク(CNN)を駆使して訓練したものです)
#loaded_model =load_model('buki-classification.h5')
#TFlite: モデルの読み込み
interpreter = tflite.Interpreter(model_path="buki-classification.tflite")
#TFlite: モデルのテンソルへの割り当て
interpreter.allocate_tensors()
#TFlite: 入力の詳細の取得
input_details = interpreter.get_input_details()
#TFlite: 出力の詳細の取得
output_details = interpreter.get_output_details()
# データベースをdataframeとして読み込み (Pandas使用)
f_name_in = "buki-spe-list.csv"
df = pd.read_csv(f_name_in, index_col=0, encoding="Shift-JIS")
name_buki = df["name_J"].tolist()
name_special = df["func"].tolist()
filename_special = df["fname_func"].tolist()
categories = df.index.values.tolist()
# 音声合成ライブラリpyttsx3の初期化
#engine = pyttsx3.init()
# pkill com.termux.api
# 音声のスピード調整
#rate = engine.getProperty('rate')
#print('デフォルトの音声スピード: {}'.format(rate))
#engine.setProperty('rate', 200)
while True:
#input("Enterキーを押したら実行")
print("ファイルが更新されたら実行されます")
list_of_files =glob.glob('/sdcard/Pictures/Screenshots/*')
latest_file = max(list_of_files, key=os.path.getctime)
old_l_file=""+latest_file
while (latest_file == old_l_file):
old_l_file=""+latest_file
list_of_files =glob.glob('/sdcard/Pictures/Screenshots/*')
latest_file = max(list_of_files, key=os.path.getctime)
plt.close()
time.sleep(0.9)
# プレイ中画像読み込み
#img = cap_camera_to_img()
img_pil = Image.open(latest_file)
if img_pil.mode == 'RGBA' or "transparency":
img_pil = img_pil.convert('RGB')
img_pil_array = np.array(img_pil)
img = img_pil_array[:,:,[2,1,0]]
# スクリーンショットの大きさに応じて不要部分をカット
img_cut = img[cap_Top:cap_Bottom, cap_Left:cap_Right]
# 画面右上に表示される相手側のブキ画像4個を切り出してXPdataに格納
XPdata, Img_cut_org = cut_img_to_XPdata(img_cut)
#プレイ中画像の予測 (Tensorflow使用)
#predicted_labels = loaded_model.predict_on_batch(XPdata)
predicted_labels=[]
for i in range(4):
#TFlite バッチ次元の追加と型変換 (エラー文の仰せに従い変換)
#XPdata_tmp=XPdata[i]
XPdata_tmp= np.expand_dims(XPdata[i], axis=0).astype("float32")
#TFlite 入力画像のセット
interpreter.set_tensor(input_details[0]['index'], XPdata_tmp)
# TFlite 処理実行
interpreter.invoke()
# TFlite 出力の取り出し
predicted_labels.append( interpreter.get_tensor(output_details[0]['index']) )
# 予測結果はベクトルなので、それを数値に変換 たとえば
# predicted_labels[?] = [1,0,0,0,0,0,0,0....,0,0]
# → predicted_no[?]= 0
# predicted_labels[?] = [0,0,0,0,1,0,0,0....,0,0]
# → predicted_no[?]= 5
predicted_no = []
for i in range(4):
predicted_no.append(np.argmax( predicted_labels[i] ))
# 取り込んだ画像と予測categoriesの表示
show_predict_buki(predicted_no, Img_cut_org)
# 画像の保存
save_cut_img(predicted_no, Img_cut_org)
# ブキの名前発音
speak_buki(predicted_no)
# スペシャルの名前発音
speak_special(predicted_no)