( ※ 更新・はてなブログから引っ越し: '24/8/16 )
しょくぶつ(^^)です。 さあっ ! いよいよ「スプラトゥーン3のプレイ映像を機械学習で分析。対戦相手のスペシャルを声でお知らせ。」を実行します。
ここまで来れば実行だけは簡単です。
Windows PCは前回の記事と同じく、10年前の古いものでも大丈夫ですよ。
(1) 次のURLに私が作成したファイルをアップロードしました。ここからファイルを3つ、ダウンロードしてください。
※ 更新: 「2024夏 Sizzle Season」で増えたブキとスペシャルに対応できるよう、学習データを更新してあります。
- buki-classification.h5
- csvファイル
- CNN-predict-public.py
(2) ファイルを同じフォルダに置いてください。
(3) 前の記事と同じ構成で、機器を接続してください。
(4) spyderで”CNN-predict-public.py”を開いてください。
(5) 前回の記事と同じようにコード中の cap_dev_no = ? を変えてください。
(6) コードを変更します。
キャプチャー機器の説明書を見て、読み取り解像度を設定してください。
私が使ったエレコムのAD-HDMICAPBKだと、少なくとも次の2パターンが可能でした。
パターン1
cap_W = 1920
cap_H = 1080
パターン2
cap_W = 1280
cap_H = 720
(7) Run file(F5)してください。 Run file(F5)したあと、10秒くらいしてから、"Enterキーを押したら実行"と表示されます。 そしてEnterを押すと、2~3秒もすれば読み取ったブキ名とスペシャル名を発音します。
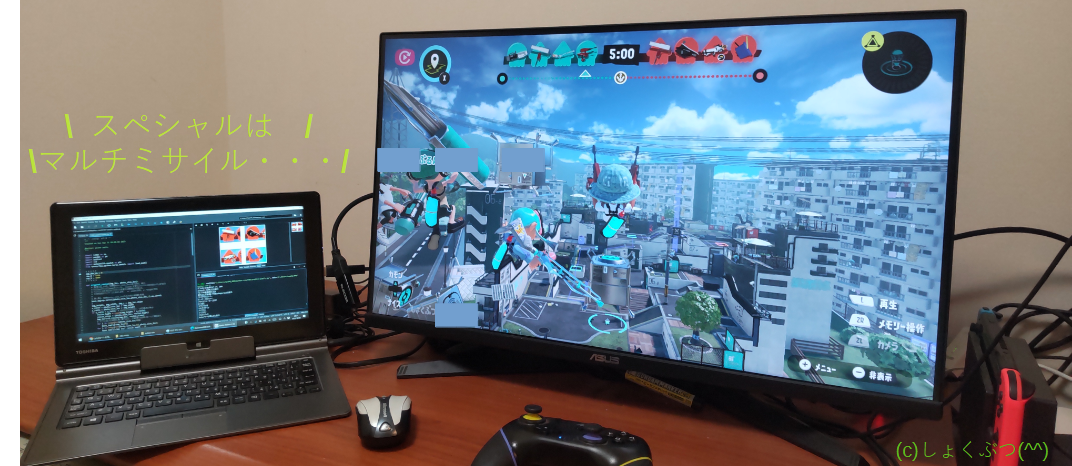
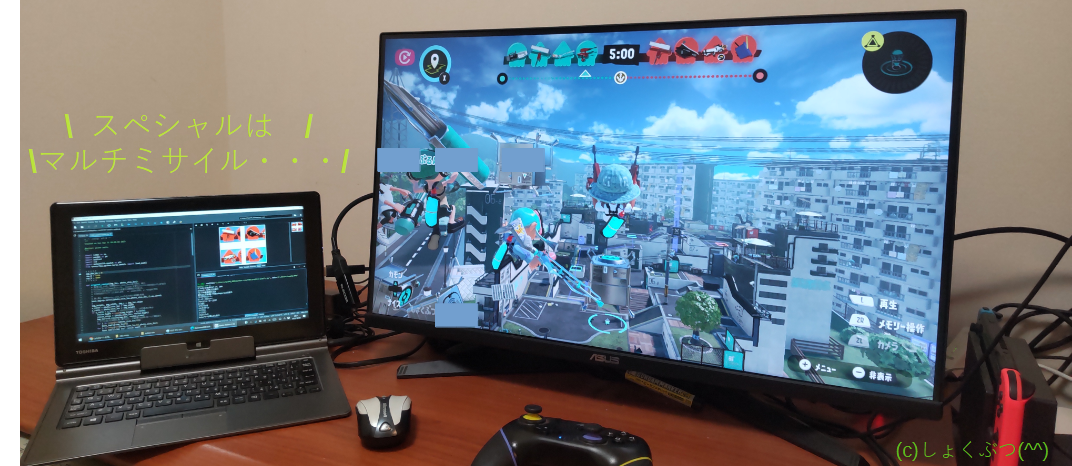
注意) "Enterキーを押したら実行"は試合中の画面(例えば上の図)が出てからにしてください。うまく動かないのは、たいてい、上記(6)の設定ミスです。
(8)コードについて
(8)コードについて
コード内で記載の通り、予測モデルは機械学習、具体的には 畳み込みニューラルネットワーク(CNN)を駆使して訓練して作成しています。
今回のコードでは予測モデルを使うだけなので、
・tensorflow.python.keras.models の load_model でモデルを読み込み
・predict_on_batch で XPdata に格納した画像からブキ名を予測
という、たった2行で予測ができています。
もし機械学習が無ければ、大まじめに、
・背景の除去 (古いPCだと1画像あたり10秒 ? )
・各ブキ画像との比較
・圧縮画像のノイズ対策
・試合進行に伴うブキ画像の拡大・縮小対策
・正確な切り取り位置合わせ
などをコード化する必要があるわけです。
Python初心者には難しかったと思います。もしかするとPythonというよりはプログラム初心者の方も読んでいるのでしょうか?
そんな方は、まずは最終行の
speak_special(predicted_no)と、その4行上の
show_predict_buki(predicted_no, Img_cut_org)を入れ替えて、先にスペシャルの名前発音を試すところから始めるといいかもしれませんね。 元のままだと、試合開始直後に"Enterキーを押したら実行"しても、スペシャル発音のタイミングで遅くて、相手が既にスペシャルを発動していたりするんですよね。
もうすこし詳しい方は、発音後に、スペシャルのイラストも表示できように改造してはどうでしょうか? サブの発音・表示もできるようにするといいですね。
更に詳しい方は、あまり負荷が増えない程度に、camera.read()をループし続けるように改造してみてください。 カメラのバッファーを溜め続けないためで、これをやるとcamera.read()はだいぶ早くなります。
今回は本題の実行が目的なのでコードの詳細は省略しました。 でもコードの中にコメントを多く入れたので、頑張れば理解できるはずです。 コード詳細が知りたい方はリクエストください。
本題の実行そのものは、これでおしまいです。 次回以降は、どうやって予測モデルを作ったか、その方法を少しずつ、書いていきます。 よくある機械学習の記事とは違い、自分で学習データをゼロから用意するという激闘編も予定しています。 それとも、もっと使いやすいツールに改造しましょうかね ? ブキ分析以外をやってみますかね ?
# -*- coding: utf-8 -*-
"""
Created on Sun Sep 31 10:00:14 2023
@author: plant-smile
"""
import numpy as np
import pandas as pd
import pyttsx3
import cv2
import matplotlib.pyplot as plt
from tensorflow.python.keras.models import load_model
# # # # #
cap_dev_no = 1
cap_W = 1920
cap_H = 1080
# # # # #
def original_resize(img_loc, photo_size_loc):
# 画像img_locを、縦横photo_size_locの正方形に、縮小
# Pillow(PIL)のImageモジュール, resize を使うとアスペクト比が変わってしまうので、
# アスペクト比を変えないでサイズ変更する関数を作りました。
# 予測性能がアップ? した気がします。 x: width方向, y: height方向
#
# 真っ黒な、縦横photo_size_locの正方形の画像を用意。
base_img=np.zeros((photo_size_loc,photo_size_loc,3),np.uint8)
#
img_height, img_width, img_c = img_loc.shape
x_ratio = photo_size_loc / img_width
y_ratio = photo_size_loc / img_height
if x_ratio < y_ratio: # widthの方が大きい、つまり横長の場合
resize_heght = round(img_height * x_ratio)
resize_sizes = (photo_size_loc, resize_heght)
img_loc=cv2.resize(img_loc, resize_sizes)
# 上下に空いた隙間は真っ黒ではなく、元画像の端部をコピーして埋めます。
for i in range(int(photo_size_loc/2)):
base_img[i]=img_loc[0]
for i in range(int(photo_size_loc/2),photo_size_loc):
base_img[i]=img_loc[ resize_heght - 1]
# base_img と img_loc を合成
height0 = int( ( photo_size_loc-resize_heght )/2 )
base_img[height0:resize_heght + height0,:,:]=img_loc
else: # 縦長の場合 今回は縦長にはならないはずですが、念のため。
resize_size = (round(img_width * y_ratio), photo_size_loc)
# base_img と img_loc を合成
img_loc=cv2.resize(img_loc, resize_size)
base_img[0:resize_size[1],0:resize_size[0],:]=img_loc
return(base_img)
def cap_camera_to_img():
print("プレイ中画像読み込み")
camera = cv2.VideoCapture(cap_dev_no,cv2.CAP_DSHOW)
camera.set(cv2.CAP_PROP_BUFFERSIZE, 1) # バッファーを少なくする(デフォルトは3)
camera.set(cv2.CAP_PROP_FRAME_WIDTH,cap_W)
camera.set(cv2.CAP_PROP_FRAME_HEIGHT,cap_H)
ret, img_loc = camera.read()
camera.release()
return(img_loc)
def cut_img_to_XPdata(img_loc):
# 画面右上に表示される相手側のブキ画像4個(幅:高さ=80:64=5:4)を切り出してXPdataに格納
# すこし大きめに切り出している理由は、ガチマッチ進行によるブキ画像の拡大表示に対応するため。
XPdata =[]
Img_cut_org = []
Htop, Hbottom = int(16/720*cap_H), int((16+64)/720*cap_H)
Wtop = int(692/1280*cap_W)
for i in range(4):
Wbottom = Wtop + int(80/1280*cap_W)
img_cut = img_loc[Htop: Hbottom, Wtop: Wbottom]
# オリジナルのカット画像の保管(ファイル保存したいとき用)
Img_cut_org.append (img_cut)
# サイズを64x64に統一
img_cut = original_resize(img_cut, 64)
XPdata.append (img_cut)
Wtop = Wtop + int(59/1280*cap_W)
# np.arrayが必要な理由。
# 1. tensorflowで作成したモデルへの入力はnp.arrayである必要があるため。
# 2. [NParray,NParray,NParray,NParray,]というリストを
# (4, 64,64,3)のnp.array of unit8に、、さらに/255することでfloat64 に変換するため。
XPdata=np.array(XPdata)/255
return(XPdata, Img_cut_org)
def show_predict_buki(predicted_no, Img_cut_org):
print("取り込んだ画像と予測categoriesの表示")
# Pillow(PIL)を使って4個のブキ画像を並べて表示します。
plt.figure(figsize=(15,15))
for i in range(4):
plt.subplot(2,2,i+1)
plt.xticks([])
plt.yticks([])
img_cut = cv2.cvtColor(Img_cut_org[i], cv2.COLOR_BGR2RGB)
plt.imshow( img_cut )
plt.xlabel( categories[ predicted_no[i] ] )
plt.show(block=False)
def speak_buki(predicted_no):
# ブキ名を発音します。
for i in range(4):
engine.say( name_buki[ predicted_no[i] ] )
engine.runAndWait()
print( name_buki[ predicted_no[i] ] )
def speak_special(predicted_no):
# スペシャル名を発音します。
engine.say('スペシャルは')
engine.runAndWait()
print('スペシャルは')
for i in range(4):
engine.say( name_special[ predicted_no[i] ] )
engine.runAndWait()
print( name_special[ predicted_no[i] ] )
if __name__ == '__main__':
# モデル読み込み (Tensorflow使用, 畳み込みニューラルネットワーク(CNN)を駆使して訓練したものです)
loaded_model =load_model('buki-classification.h5')
# データベースをdataframeとして読み込み (Pandas使用)
f_name_in = "buki-spe-list.csv"
df = pd.read_csv(f_name_in, index_col=0, encoding="Shift-JIS")
name_buki = df["name_J"].tolist()
name_special = df["func"].tolist()
filename_special = df["fname_func"].tolist()
categories = df.index.values.tolist()
# 音声合成ライブラリpyttsx3の初期化
engine = pyttsx3.init()
# 音声のスピード調整
rate = engine.getProperty('rate')
print('デフォルトの音声スピード: {}'.format(rate))
engine.setProperty('rate', 200)
while True:
input("Enterキーを押したら実行")
plt.close()
# プレイ中画像読み込み
img = cap_camera_to_img()
# 画面右上に表示される相手側のブキ画像4個を切り出してXPdataに格納
XPdata, Img_cut_org = cut_img_to_XPdata(img)
#プレイ中画像の予測 (Tensorflow使用)
predicted_labels = loaded_model.predict_on_batch(XPdata)
# 予測結果はベクトルなので、それを数値に変換 たとえば
# predicted_labels[?] = [1,0,0,0,0,0,0,0....,0,0]
# → predicted_no[?]= 0
# predicted_labels[?] = [0,0,0,0,1,0,0,0....,0,0]
# → predicted_no[?]= 5
predicted_no = []
for i in range(4):
predicted_no.append(np.argmax( predicted_labels[i] ))
# 取り込んだ画像と予測categoriesの表示
show_predict_buki(predicted_no, Img_cut_org)
# ブキの名前発音
speak_buki(predicted_no)
# スペシャルの名前発音
speak_special(predicted_no)